
2014.10上海大数据采集培训班(培训地点:上海图书馆教育培训中心)
可以先学习,后付费,拿到发票后再银行转账
一 培训目的
信息的发现 、选择、收藏、组织和分享是图情工作人员最重要的工作之一,尤其是在大数据时代,只有做好这方面的基础工作,才能满足领导的战略决策需要,满足教学科研的需要,满足读者个性化信息服务的需要。
在大数据时代,图书馆员只有快速的向数据科学家和领域专家转变,打破图书馆的传统边界,建立各种数据联盟,才能适应时代的发展。
大数据具有信息种类多,更新速度快,综合价值大等众多特性,如何精选真实、更有价值的信息,更快、更方便的采集、聚合各种信息,进而进行存储、分析是图情工作人员面临的重要挑战。
为此,特举办一系列大数据培训班:虚拟化及云计算、大数据采集、信息可视化、数据挖掘等,首先开办大数据采集培训班。
本次培训班将详细讲解Rss、Xpath ,Drupal 、Offline Explorer 、aTube Catcher 、Lucidworks等相关技术和专业软件使用。认真参加培训的老师,将能熟练的掌握数据采集的技巧,并熟悉数据挖掘的部分技能,为将来工作带来极大便利。
二 课程概述
主要讲课内容是以为中国大陆两个最顶级的科研机构实施的数据采集项目为例,详细讲解如何对同行机构、行业学会、国际协会、各国相关政府部门、重点综合性科学出版物、重点网站、试验项目和实验设施等的新闻、论文、会议报告、分析评论、预印本、案例研究、多媒体、图书、招聘信息等进行快速的抓取、聚合及整合搜索。
课程特色:
1 经过了实践考验,是成功案例的真心分享
本课程是在给国内最顶尖的科研机构所做信息搜集案例的真心分享,反响强烈,甚至在一家单位多次做同样的分享。
2具有较强的可操作性
大部分软件具有非常便捷的操作性,简单方便。高级操作有写好的运行模版,不懂编程的,也可熟练操作。
3 具有低成本、可持续性
几乎用到的所有软件都是开源或免费软件,而且这些软件更新发展的速度很快,能不断满足信息采集的需求。
三 培训对象
适合对象:凡是从事战略研究、参考咨询、图书馆采编部门等工作的图情工作者都可参加。任何致力于![]()
![]()
![]() 更好数字化生存的机构和个人均欢迎参加。
更好数字化生存的机构和个人均欢迎参加。
四 时间、地点和培训费用
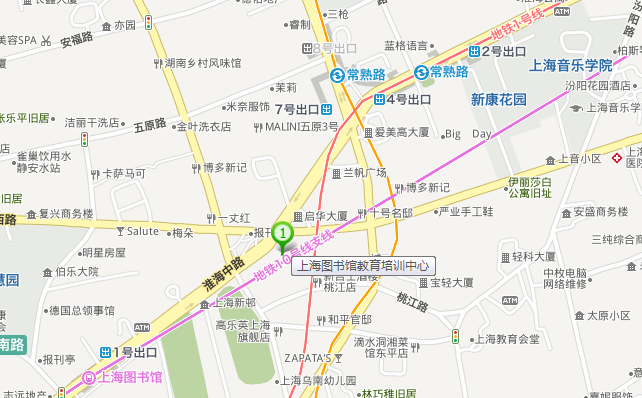
地点:淮海中路1413号(复兴中路口)上海图书馆教育培训中心
附近交通:公交15、26、45、49、93、96、167、236、824、830、911、920、926、927、轨交一号线、七号线(常熟路站)、十号线(上海图书馆站)
时间:2014.10.20-10.24
费用:1500元(含教材费用),学生半价(含教材费用)食宿自理,欢迎团体报名,价格优惠
五 培训回执
![]()
![]() 参会请于2014年10月20日前填写回执,反馈至QQ或会务联络信箱:cuikejun@qq.com,需要住宿的老师,请在回执上填写注明,可统一提前预定。
参会请于2014年10月20日前填写回执,反馈至QQ或会务联络信箱:cuikejun@qq.com,需要住宿的老师,请在回执上填写注明,可统一提前预定。
联系人:崔克俊 13681445347 13381113196 QQ:372948992
|
姓名 |
性别 |
职务 |
|||||
|
单位 |
电子邮箱 |
||||||
|
地址 |
|||||||
|
发票抬头 |
|||||||
|
发票项目 |
可开 培训费 会务费 资料费等 |
||||||
|
联系电话 |
固定电话: 手机: |
||||||
|
是否住宿 |
住宿要求: □合住 □单间 |
||||||
北京亚艾元软件有限责任公司(主办)
2014年8月5日
附件一 讲课提纲
讲课提纲
第1天内容
|
第1天 |
9:00-10:00 |
先睹为快,数据采集的2个成功案例以及如何利用数据采集技术做好学科服务、知识个性化服务 |
|
第1天 |
10:30 到11:30 |
全球智库排名报告解读以及根据实际情况灵活确定信息采集的类型,制定信息采集策略, |
|
第1天 |
2:00-3:00 |
如何对Youtube某一频道、某一主题的视频快速批下载,如何去国家图书馆、中科院图书馆以及中国科学技术信息研究所这些免费开放的图书馆去检索和下载各种相关数据库
|
|
第1天 |
3:30-4:30 |
利用电骡emule、迅雷下载各种资源以及Drupal在信息采集、组织和服务的介绍以及国外案例介绍 |
![]() 第2天内容
第2天内容
|
第2天 |
9:00-- 10:00 |
安装Drupal采集器 |
|
第2天 |
10:30 到11:30 |
利用Drupal采集器,采集新闻数据 |
|
第2天 |
2:00-3:00 |
Drupal Feeds模块基础知识介绍,抓取器、解析器、处理器 |
|
第2天 |
3:30-4:30 |
使用导入节点、分类、用户 |
![]() 第3天内容
第3天内容
|
第3天 |
9:00-- 10:00 |
讲解如何使用Feeds,抓取图片,如何控制图片的文件名、存储路径 |
|
第3天 |
10:30 到11:30 |
讲解如何使用Feeds tamper对数据进行预处理 |
|
第3天 |
2:00-3:00 |
Xpath规则实例解析,根据5个实例网站,讲解常用的Xpath知识。 |
|
第3天 |
3:30-4:30 |
如何使用feeds_crawler采集分页结构的列表页面 |
![]() 第4天内容
第4天内容
|
第4天 |
9:00—10:00 |
如何实现对采集过来的网页内容的自动标引,根据种子本身的设置,自动继承
|
|
第4天 |
10:30 到11:30 |
feeds_selfnode_processor、feeds_smartparser、feeds_batch模块使用介绍 |
|
第4天 |
2:00-3:00 |
以Drupal采集器为基础,实现当当图书抓取。 |
|
第4天 |
3:30-4:30 |
以Drupal采集器为基础,实现当当图书抓取。 |
![]() 第5天内容
第5天内容
|
第5天 |
9:00-- 10:00 |
利用Lucidworks Fusion对数据进行搜索和挖掘 |
|
第5天 |
10:30 到11:30 |
利用Lucidworks Fusion对数据进行搜索和挖掘 |
|
第5天 |
2:00-3:00 |
行业主题词表和分类表在信息组织和挖掘中的重要作用 |
|
第5天 |
3:30-4:30 |
大数据时代如何更好的进行专题服务、个性化服务以及发表相关论文注意事项 |